Aplikace Scraping Camel byla vyvinuta firmou Shopitak, která se zaměřuje na vývoj aplikací pro ekosystém Mergado. Cílem aplikace je projít HTML kód dané stránky a získat z něj libovolná data v reálném čase, které uloží a vygeneruje do jednoho výstupního CSV souboru.
Díky Scraping Camelu se dostanete k informacím, které nenajdete v XML feedu.
Z webu můžete získat jakákoliv data, záleží jen na vás, co zrovna potřebujete a jak moc budete kreativní. Zjistit můžete například title, meta description, nadpisy H1 a H2. Dále můžete ze stránek získat ID značky Google Analytics či Google Tag Manageru. Scraping Camel se dá využít i na reklamní DSA kampaně, které jsou postavené na datech z feedu.
Aplikace je vhodná téměř pro všechny — na své si přijdou jak SEO specialisté, tak i odborníci na PPC reklamu a technicky zdatnější uživatelé, kteří mají e‑shop.
Jak funguje aplikace Scraping Camel
- Zvolte si doménu, kterou má aplikace procházet.
- Proveďte její ověření, které je podobné jako u Google. Na výběr máte z vložení souboru na web, META značky do stránek či DNS záznamu.
- Vložte sitemap.xml, které je podmínkou pro fungování aplikace. Scraping Camel odsud bere URL stránky webu.
- Nastavte si frekvenci procházení webu — příliš mnoho dotazů může web přetížit a málo naopak zpomalit.
- Zvolte, jaké elementy chcete získat z cílových HTML stránek. Výchozí jsou title, meta description nebo si nadefinujte vlastní elementy (prostřednictvím regulárního výrazu nebo uvedením textu před a za hledanými informacemi).
- Nastavte si, jak se ve výstupním CSV mají jmenovat elementy se získanými informacemi.
- A je to. Aplikace začne procházet cílový web. Až ho celý zpracuje, vygeneruje výstupní CSV a v administraci uvede jeho adresu.
Jak použít aplikaci Scraping Camel?
Na testovacím e‑shopu vám ukážeme, jak jednoduše získáte SEO data a popis produktu.
Postup
- Kliknete na záložku “Editovat elementy”.
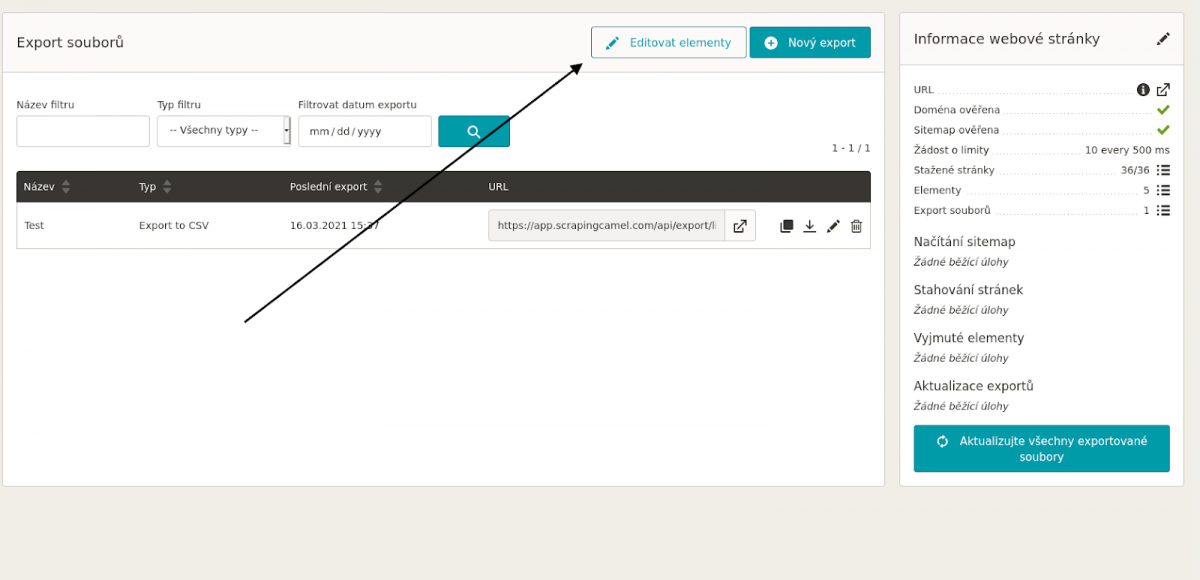
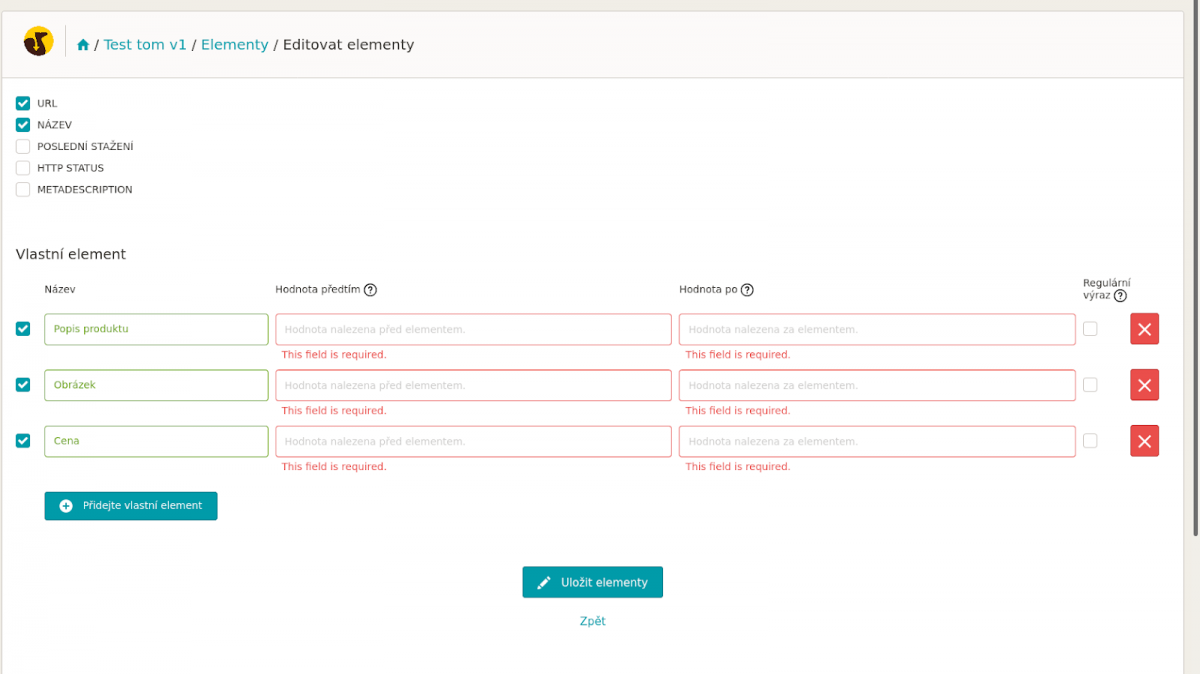
- Kliknete na “Přidejte vlastní element” a elementy si pojmenujte podle vašich preferencí.
- Přejdete na váš web, ze kterého chcete data získat a stiskněte klávesu CTRL+U.
- Tato klávesová zkratka vám umožní vidět zdrojový kód webu, který je potřeba k nadefinování elementů.
- Pomocí vyhledávací klávesové zkratky CTRL+F, vyhledejte požadovaný element, který chcete získat. V našem případě budeme chtít najít popis produktu, tedy: <h3>Detailní popis produktu</h3>
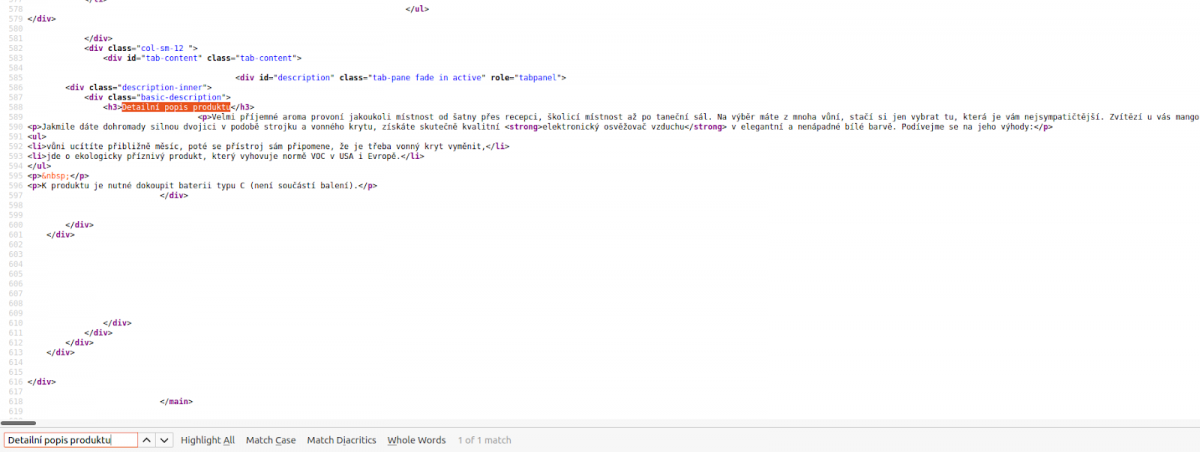
- Přejdete zpátky do aplikace
- Do “Hodnoty před” zadejte: Detailní popis produktu a do “Hodnoty pod” zadejte .

- Aplikace primárně neslouží k prohlížení dat a je potřeba na to myslet. Proto doporučujeme, abyste data prohlíželi v jiném programu, například Mergadu nebo Google sheet. Stejný postup se aplikuje i na další prvky, které budete chtít z webu získat.

Na podobném principu funguje i aplikace Screaming Frog a Xenu. Tyto aplikace fungují na jednorázovém principu a spouštějí se na lokálním zařízení. Námi zmiňovaná aplikace Scraping Camel funguje přesně naopak — běží na serveru nonstop a výstupy poskytuje ve strojově čitelné podobě, které lze následně ještě zpracovat dalším softwarem.
Proč používat aplikaci Scraping Camel?
- neustálý monitoring změn
- funguje na serveru (nonstop)
- lze nahrát do Mergada jako vstupní soubor pro export
- neomezený počet webů na jeden účet
Tak jako u většiny aplikací, i tady existuje pár omezení:
- aplikace funguje pouze na základě HTML
- princip extrakce dat je na základě znaků, né tedy na základě elementů.
- podmínkou pro používání aplikace je funkční soubor sitemap.xml a ověřená doména
Pokud máte nějaké další otázky, neváhejte nám napsat do komentářů.
Komentáře (0)